Bringing DPPs to Language Models
by Manuel de Prada Corral
8 min read
These are my structured thoughts and research process in applying DPPs to language models.
Theory
The high level idea is to sample sets from an universe with probability
Distributions over sets are called sampling designs, a term that comes from survey sampling theory. They naturally model sampling without replacement.
- Given a set and a distribution over , a sampling design is a distribution over the power set that associates each concrete subset with a probability , such that and .
In simpler terms, rather than sampling one item at a time (as in i.i.d. sampling), it specifies the probability of jointly drawing a subset of items. The probability of each subset could be whatever, but it is often useful to reflect the quality of the items in the subset, i.e., . Note that we are abusing notation here, as is a different distribution over the universe, not the sampling design.
Determinantal Point Processes
-
A determinantal point process (DPP) is a sampling design with the following mass function over subsets : where is a PSD matrix, and denotes the square submatrix indexed by . Efficient algorithms exist for normalization, sampling, and marginalization, but not for maximization. Computing the most likely sub-determinant is NP-hard.
-
A -DPP is a DPP that constrains where is a parameter.
Typically, we define with the following quality-diversity structure: where is a quality measure and a feature vector such that characterizes the similarity between . Typically, and we set .
With this parametrization, the DPP mass function becomes
where abusing notation, is the matrix of feature vectors of the elements in .
Technical details about DPPs parametrizations and sampling algorithms (for reference)
The matrix parametrization
For any DPP defined by a PSD matrix such that , there is a corresponding matrix . The parametrization is more direct:We do not use it because not all PSD matrices are valid matrices, they must also have their eigenvalues in .
Sampling algorithm for DPPs
The most common algorithm to sample from a DPP relies on the eigendecomposition of :- Sample indices using a Conditional Poisson with parameters .
- Take the corresponding eigenvectors . While there are eigenvectors left, do:
- Sample an index with .
- Pick any eigenvector such that .
- Compute new , that is, orthogonalize with respect to .
Factorizations of the matrix for the parametrization
Let and . We can factorize as We can also define . Now, we can writeDual representation of the L parametrization
What if we multiply the other way around? This is called the dual representation of the DPP. Since and share eigenvalues and their eigenvectors are related by , we can sample from the DPP using .The diversity-likelihood tradeoff
If we sample from a language model using sampling techniques, we can actually draw a diversity-likelihood Pareto frontier:
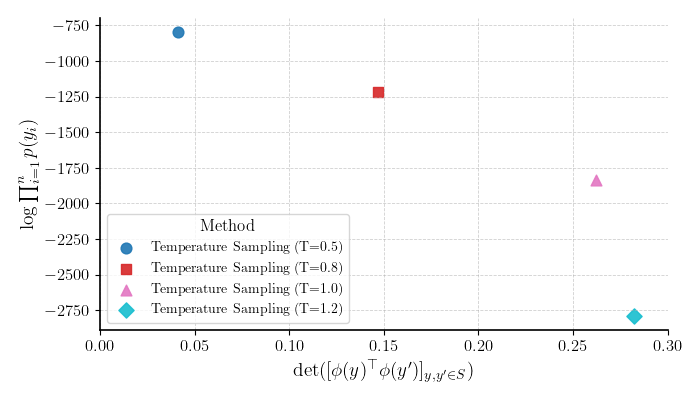
The diversity modeling is done implicitly as low temperature sampling reduces entropy, concentrating the mass on a few high-likelihood tokens. Note that applying a temperature to the step-wise softmax is not the same as applying it to the global distribution over strings.
The global K-DPP
What our parametrization of a DPP fundamentally does is to sample diverse sets from a discrete universe that has a quality measure. Ideally, we would like to define the DPP over the entire universe of possible strings :
Of course, we cannot instantiate this matrix, which is needed to perform normalization and sampling. The following research log details our attempts to circumvent this issue.
Research log
October-November: Shah algorithm
- Idea: approximate the global DPP by iteratively instantiating a local DPP over next-token distributions. Related to Sequential Monte Carlo, Importance Sampling, Stochastic Beam Search.
- Shah & Kroese (2018) promises that any step-wise-applied set distribution converges to the global set distribution, in the sense that the final samples can be used to unbiasedly estimate expectations over the global distribution.
- It is similar to Conditional Poisson Stochastic Beams, both do [step-wise process global estimator], but Shah allows any set distribution.
- Problem: as in SMC, resampling induces path degeneracy. In SMC we don't care, as only one sample is produced at the end by sampling from the particle weights. However, here is crucial that we keep diversity among trajectories.
- The algorithm is indeed diverse within last tokens, but eventually particles collapse to a common ancestor.
- In fact, it is probable that CPSB also suffers from the same issue. Evaluating in translation tasks is very blind to path degeneracy.
- Stochastic Beam Search does avoid path degeneracy. It explicitly models early commitment to a path, and is approximately equivalent to parallel ancestral sampling rejecting duplicates. Worth studying if it can be adapted...
December - mid January: Trying to fix Shah
- Heuristic Fix 1: Change the quality measure to be the next-token probability instead of the whole accumulated sequence probability. This way, the fact that some paths accumulate much more mass than others does not produce the degeneracy.
- Problem: Instead of degenerating to the highest-likelihood paths, it degenerates to low-entropy paths, that concentrate mass on a few tokens.
- Heuristic Fix 2: force different paths by taking the prefix embedding . Now sibling nodes cannot be chosen together, as they share embedding and would cause a zero determinant to any set that includes them both.
- No more degeneracy, but not a solution. The diversity evaluation is only using prefixes, thus the next-token selection is blind to diversity.
- Heuristic Fix 3: Intervene the local L matrices. What if we take the original formulation of the L matrix, compute the matrix, and then intervene it to enforce no-sibling selection while keeping the rest of the structure?
- This is a good idea, but such intervention creates non valid matrices (eigenvalues outside ).
- Abandoned possible fix: use semi-definite programming to find the closest valid matrix to the intervened one.
January-February: step-wise Shah is hard, lets first do a subpopulation-based approach
Core idea: Sample a subpopulation of and use it to build a DPP that approximates the global DPP. The subpopulation is sampled i.i.d. from with . The naive approach is to define that approximates the global :
-
Problem 1: for a string to be sampled, it must first be sampled into and then selected by the DPP. That is,
-
Problem 2: Even if we define so that , we still have to remove duplicates from to avoid zero determinants. If we do so, we are not sampling proportional to anymore. To adjust for this, we can correct the matrix by the probability of a string being selected at least once in the ancestral sample, i.e., . Once you do that, the approximate matrix is non-PSD again 🙃.
- TODO: are duplicates really a problem? shouldn't the DPP just ignore them?
-
Alternative non-working idea: do Importance Sampling over sets. Have some other set proposal distribution and then score them with the DPP. The surprising roadblock is that despite having multiple sampling-without-replacement algorithms for LMs, which have unbiased or exact sampling algorithms and inclusion probabilities, none of them can compute for a given set. A stochastic method similar to the ones employed for the inclusion probabilities should be developed. Without it, we cannot compute the importance weights.
-
Solution: work with the Dual DPP. Instead of building and correcting so that the end distribution is , estimate the matrix using Monte Carlo. Then, sample from the Dual DPP.
- This works! We can compute the DPP. However, it seems to sit in the Pareto frontier, not above it.
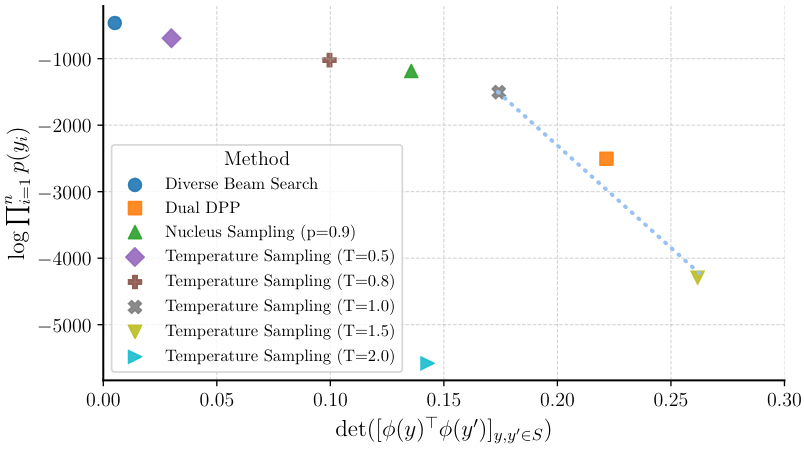 The dual DPP computes more diverse sets but also less likely ones. Let's try to draw the whole frontier. How do we parametrize the Dual DPP into a curve?
The dual DPP computes more diverse sets but also less likely ones. Let's try to draw the whole frontier. How do we parametrize the Dual DPP into a curve? - Two ways of doing this:
- Ryan suggests just getting a different set for each temperature, estimate a new matrix, and then sample from the Dual DPP.
- Tim suggests to estimate the matrix using Monte Carlo, apply a temperature to the matrix, and then sample from the Dual DPP.
- This works! We can compute the DPP. However, it seems to sit in the Pareto frontier, not above it.
-
todo:
- derive ancestral samples from 10k samples
- analyze importance weights problem
- write about the NP hardness of applying temperature to a DPP
- write about my enhanced diversity algorithm by using an approximate DPP maximizator.